第1天 2016年7月1日 周五 项目内容
今天,戎烈锋学长通知我到实验室来一趟,说是要讲讲我们正在做的项目和相关的介绍。学长介绍说,我们即将要做的项目是给北京市科委开发的外文文献知识发现系统,其中包括文档检索,知识热点,前沿技术,成果追踪四大块。学长给我演示了一下这个系统的功能,我感觉这个系统的功能还是比较完善,但在一些细节上还做的不够好。学长说以后可能会需要我们在现有的基础上新增一些功能,让整个系统功能更丰富。
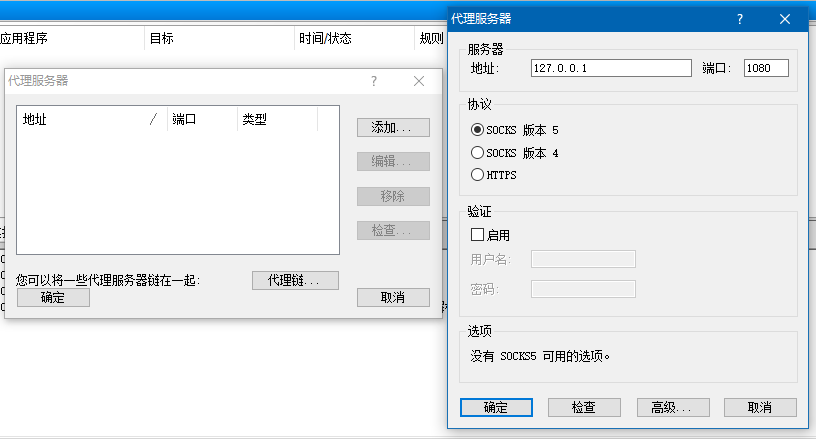
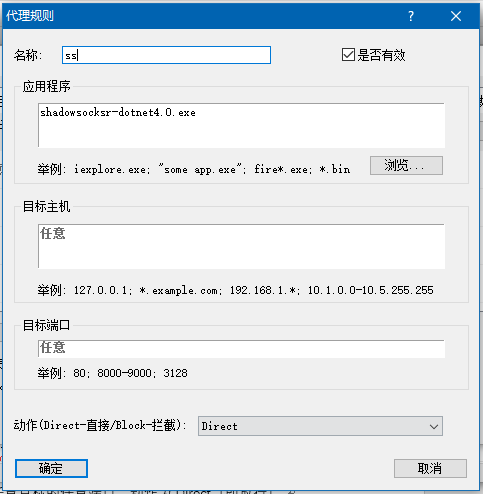
然后,学长跟我简单介绍了开发的环境。整个系统是一个网站,前端用的是HTML和JQuery,后端用的JFinal框架和Freemarker,服务器采用Tomcat部署,搜索功能利用了部署在分布式集群上的ElasticSearch。我的主要的工作是修改前端和后端。学长说主要的开发语言是Java,还需要一点HTML的知识。学长建议我这个周末下载一个Eclipse for Java EE并且配置好Java环境,方便以后的学习和使用。同时还要准备一个SSH客户端,在Windows下可以用putty,方便部署工程文件。
晚上回到寝室,我就下载了Eclipse for Java EE,根据网上的教程配置好了Java环境,写了个简单的Demo,可以运行成功。然后下载安装了putty。整个过程还算比较顺利。
第2天 2016年7月4日 周一 组会1
今天,戎烈锋学长通知我今天晚上有组会,并且组会定在每周周一,没有特殊情况都照常进行。
晚上,我按时到达开会地点。开会的有童咏昕老师,我们届的除了我之外有王立彬和符美潇,还有实验室的研究生和博士生。周一晚上的组会比较简短,基本上是个人汇报自己的进度。在会上,我认识了符美潇,他和我一起完成外文文献知识发现系统的项目。
组会结束之后,戎烈锋学长单独和我们开了一个小的会议。考虑到我们用到的是JFinal框架,所以这周我们需要自学JFinal框架的相关内容。戎烈锋学长给我们了一份JFinal的用户手册,供我们参考。同时他还建议我们结合现有的项目一起看用户手册。由于工程代码量较大,戎烈锋学长把代码分成了两个部分,符美潇负责看知识热点部分的代码,我负责看文档检索部分的代码,并在代码中写一些注释。在周末的时候,我们互相交流一下自己的学习成果。这样的话方便我们快速的阅读代码。戎烈锋学长说,这周主要是阅读代码,也可能会给我们安排一些写代码的任务,根据我们的完成情况进行安排。
由于刚开始进行实习,工作还比较轻松,但我也不能因此而懈怠,还是要认真地学习JFinal框架,认真地阅读工程代码,为后面的工作做准备。
第3天 2016年7月5日 周二 JFinal入门
今天,我准备自学一下JFinal框架的用户手册,对JFinal框架有了一定的理解。
通过用户手册的介绍,我知道了JFinal 是基于 Java 语言的极速 WEB + ORM 开发框架。它的特点是开发迅速、代码量少、学习简单、轻量级、易扩展。JFinal使用的是MVC 架构,MVC我在之前学习Objective-C的时候也接触过,这对我现在的学习有很大的帮助。还有一个特点是自动加载修改后的 java 文件,感觉这和php的热修改很相似。JFinal框架还有多视图支持,支持 FreeMarker、JSP、Velocity等,这个项目中采用的视图就是FreeMarker。
用户手册的第一章是快速上手,里面介绍了如何运行一个实例demo。我也根据用户手册上的介绍一步一步进行操作。配置工程,添加文件,都顺利完成了,但在调试项目时,我始终得不到用户手册上的结果,无法顺利启动项目。在网上也没有查找到相关的有用的资料。于是自己重新下载安装了一遍Eclipse for Java EE,发现还是不行。折腾了半天才发现,是因为JFinal框架需要使用自定义的Debug配置,我点击的是Eclipse的Debug按钮,打开的是默认的Debug配置;正确的做法是点击右侧的小三角,选择相应的配置。看来还是得细心,要不然会把时间无谓花在解决这些问题上。
第4天 2016年7月6日 周三 JFinal进阶
今天,我继续阅读了JFinal框架的用户手册,并结合代码能够大致理解JFinal框架的工作过程。
看了用户手册的第二章,写的是JFinalConfig相关的内容。基于 JFinal 的 web 项目需要创建一个继承自JFinalConfig类的子类,该类用于对整个 web 项目进行配置,可以配置常量、访问路由、数据库访问插件、全局拦截器、事件处理等功能。
在看第三章的时候,我就开始似懂非懂了,第四章之后更是不明白这是什么东西。用户手册写的简单而精辟,比较适合熟悉Web开发的人来阅读,对于我这样的新手,还是结合项目学习更加实际一些,于是我打开了项目。
项目中的FLKDConfig.java应该就对应着JFinalConfig。里面配置了开发模式为false;配置了路由,即各个页面对应的Java类;配置了一个Postgre SQL的连接插件;配置了类对应的ActiveRecord。没有配置全局拦截器、事件处理。有了例子,再根据用户手册上的介绍,我仿佛明白了一些JFinal框架的工作过程。
在配置中定义的这些东西正是为了方便后面的使用。配置了路由即指定了某个网页收到请求后,由哪个类的哪个方法进行响应,做出相应的动作,或渲染新的页面。使用数据库就需要配置一个C3p0数据库连接池插件,注明数据库种类,地址,端口,用户名,密码等信息。配置ActiveRecordPlugin则是为了方便数据库的读取,将数据库中的表直接与MVC中的Model类对应,可以采用一系列方法进行简单查询,也可以用DAO对象进行SQL语句查询。
第5天 2016年7月7日 周四 阅读代码-关于MVC
今天,我开始阅读项目的代码。感觉自己已经能够大致理解JFinal框架的工作过程了,工程里用到的Controller,ActiveRecord,Plugin等部分的内容我也大致熟悉了,其它部分的内容不是很理解。询问了一下学长,他说可以先不看那些部分的内容,先看项目代码。等有需要的时候,再来回头看没懂的部分。
打开项目工程文件,就看到工程中有很多个包,看得出来这个项目不像是以前我接触过的那类项目,一个人几天就能完成的。同时,对于这种大型的项目,一个好的代码风格是至关重要的。由于JFinal框架采用的是MVC模型,Model类全部放在了org.mbyd.flkd.model包中,Controller类全部放在了org.mbyd.flkd.controllers包中。在Java文件中没有找到View类的文件,后来一想,这里的View应该是HTML,可能是用Freemarker描述的文件。不出所料,果然在WebRoot/views中找到了相应的Freemarker文件。
由于工程文件众多,我觉得可以先看需要看的内容。我先把项目运行,然后打开检索页面,看到地址栏显示网址为/articles/search,于是我先查看FLKDConfig类中定义的/articles对应的类是ArticleController.class,然后在ArticleController中找到了search()方法。通过阅读方法中的代码,我知道了,先通过函数getPara()获得传入的参数,进行处理与检索后,将需要呈现在页面的元素通过setAttr()方法放置到页面中,通过render()方法指定要显示的页面。找到了查看代码的方法,接下来的阅读代码的工作也会更加顺利。
第6天 2016年7月8日 周五 阅读代码-关于Freemarker
今天,我继续阅读项目的代码,并根据需要写了一些注释。今天重点看了一下Freemarker的部分。在JFinal中有很多的HTML文件,但其实里面的内容是Freemarker。这些页面都不是完整的HTML内容,还有部分内容需要动态生成。昨天在Java代码中看到了setAttr()方法,通过这个方法设置了某些字段的值。在render方法渲染的页面文件中,用${…}标注了对应的字段所处的位置,表示对应的值应当插入到这里。同时,我也看到,项目中有一些奇怪的记号。在网络中搜索后,我发现在Freemarker中也能对字符串、数组等高级数据结构进行一系列处理,比如获得长度,遍历元素,获取元素下标、转换成HTML格式等。项目中原有还有一些地方用到了条件语句,通过学习Freemarker的语法,发现自己也能看懂这些语句表达的意思。结合运行起来的项目,我基本上明白了JFinal的工作流程了。
下午我和符美潇讨论了一下这几天学习的成果。符美潇看的是知识热点部分的代码,他说,热点的控制部分主要在HotspotController里面。发现的部分数据存在服务器中,界面上有一个二级菜单进行显示。追踪的部分主要调用的是搜索的部分,将搜索结果以多样化的方式显示在网页中,包括趋势图像,列表等。此外,热点追踪还有一个导出到word的功能,其实也是利用了freemarker的动态替换的特性,将已有的doc文档模板进行填充,最后提供给用户下载。这次讨论让我收获颇多,对热点部分的内容也有了一定了解。
第7天 2016年7月11日 周一 组会2
今天通知有组会,晚上我便按时去了。今天晚上的组会,大家先汇报了各自的工作进展,然后由师兄做了一个展示,他给我们讲了讲最近读的一篇论文以及自己思考的有哪些地方可以继续深入研究。听完之后也不是很懂,这说明我有些知识不是很明白,以后还需要多多学习。然后,童咏昕老师给我们放了学堂在线MOOC平台的计算几何课程,主讲人是清华大学的邓俊辉老师。在介绍了什么是计算几何之后,他开始向我们讲解凸包的知识,以及如何找到一个凸包。由于时间的原因,在组会上没时间放完整个课程,童咏昕老师建议我们自己课下观看。
组会完后,戎烈锋学长单独跟我们聊了聊阅读的内容以及进度,并给我们布置了新的任务。鉴于我们能够基本了解JFinal框架的内容,戎烈锋学长给我们安排了一些写代码的任务。给符美潇布置的任务是利用EChart插件,给热点部分添加一个云图;给我布置的任务是做一个注册登录的界面,可能需要在数据库中新建一个表,建议我用Navicat进行连接,并且把数据库的连接方式告诉了我。最后,我们还互相留了自己的联系方式,并且建立了一个QQ群,方便互相交流,以及可以直接在线上讨论问题。
第8天 2016年7月12日 周二 数据表设计
今天,我开始给项目增加注册登录的功能。注册登录虽然看起来很简单,但是其实还是需要考虑很多东西。我习惯于先从数据开始考虑。在登录时,用户需要输入用户名和密码,来进行登录的操作;在注册时,用户至少需要输入用户名和密码,可能还需要其它的信息。询问了戎烈锋学长之后,他说现阶段只需要注册的时候输入用户名、密码、手机号和电子邮箱。既然这样,数据库中就应该记录用户id、用户名、密码、手机号和电子邮箱这些信息。除了用户id采用int,其它的属性应该用varchar进行存储。同时,考虑到数据安全问题,我觉得数据库中的密码项应该记录密码的MD5值,这样能够提高安全性,避免了明文传输密码。
于是我下载了Navicat for Postgre SQL,成功连接上了服务器,小心谨慎地创建了一个叫user的表,创建了相应的属性。数据表就这么顺利的创建完成了。
其实仔细想想,我在数据库课程中学会了如何设计一个数据库,在计算机网络安全课程中学会了加密和消息认证的相关内容。这些都是在平常上课学到的东西,真正运用到实际的工程中,也还是需要一番思考。学以致用,才能让自己收获更多。
第9天 2016年7月13日 周三 页面和后端
今天,我继续来做注册登录的功能。昨天已经弄好了数据库,今天就先开始绘制界面吧。好在我之前就自学过一些关于HTML的知识,画起界面应该会得心应手。为了保持整个界面的统一,我就把项目的首页拷贝了一份,直接在上面进行修改,修改标题为登录,添加了一个表单,表单中有两个输入框,一个提交按钮;注册界面也是同理。然后又在注册界面和登录界面上加上了它们的跳转链接。界面很轻松就画好了。
接下来开始编写后端。首先新建一个User类作为数据库访问类,在项目配置文件中增加一个ActiveRecord,将user表映射到User类上。接着添加路由,将/login对应到LoginController类中,将/register对应带RegisterController类中。最后在相应的控制类中,编写相应的代码。在页面加载时,没有传递参数,所以基本只需要渲染页面即可。页面上通过POST方法向控制类传递请求,LoginController中需要判断输入的用户名和密码是否正确,如果正确跳转至原来的首页;RegisterController中需要判断用户名是否在数据表中存在,如果不存在则向数据库新增一个数据项目。经过一番调试,整个界面能够正常运行起来了。
今天开始写代码了,感觉比阅读代码要累一些,但是我觉得这样更有意思。以后写得熟练了,项目做得应该快一些吧。
第10天 2016年7月14日 周四 功能完善
昨天做了注册登录的功能,但是今天想想,还是有不完善的地方。
最开始我预计是在POST表单中只传递密码的MD5,而现在只是简单的传递了密码。所以我需要做一些调整。首先,在POST表单之前,就应该对密码进行处理,获得其MD5值。具体的算法我也记得不是很清楚了,于是在网上找了一个JavaScript版本的计算MD5的函数。这样就可以保证传输时没有明文传输密码。于是我清空了user表,进行了测试,发现没有问题功能正常。
还有一个问题就是我希望能够判断用户现在是否是已经登录了,如果没有登录,访问主页会自动跳转至首页。思考了半天也没想出应该怎么写,和符美潇讨论了一下,他说JFinal用户手册里有写session的内容,应该用session就可以解决。于是我回过头来看了看手册,找到了关于session的内容,经过一番学习和尝试,终于实现了这一功能。
最后我还考虑到了一个问题,作为一个未登录的用户,我可以通过网页上方的快捷导航栏直接点击进入其它页面。所以我需要对注册和登录界面,把上面的导航栏换掉。然而我查看之前写的HTML代码,并没有看到导航栏的部分。仔细阅读代码,发现第一行有一个include _layout.html,我在这个文件中,顺利看到了导航栏的内容。复制了一份之后,修改成不带导航栏的样式,再将注册和登录界面的include指向不带导航栏的样式,就这样完成了。
第11天 2016年7月15日 周五 合并代码
昨天我把注册登录部分做完了,而符美潇还有一些工作没做完。今天给戎烈锋学长看了一下,他说做的还不错。戎烈锋学长要我和符美潇各自写一下自己修改了哪些部分,方便之后代码的合并。我就凭着自己的记忆,大致写了一下。
下午,在看完符美潇那部分的工作后,戎烈锋学长说由我来把代码合并一下。他告诉了我修改了哪些部分,感觉他修改的不多,准备就根据他修改的部分,在我的代码基础上面合并。合并完成发现他的那部分不能运行。检查了一会还是没能发现问题,于是我决定在他的代码的基础上合并我的代码。虽然我修改的部分比较多,但是一旦出错,我也方便很快发现问题。花了些时间,终于合并完成了。
感觉我花了很长时间来进行两个人代码的合并,要是团队里人多起来,人工合并代码就变成一件麻烦的事情了。两个人的代码没有太多重合的部分,合并起来冲突的地方也少,一个团队很多个人,合并代码时肯定会出现冲突,比如重名变量,语句的保留与删除等。其实我觉得,合并代码这件事,不如交给机器去做,既省时,又省力,现有的Github就是一个很好的平台。我向戎烈锋学长提出了建议使用Github,学长也说我们也着手准备把项目放到Github上去。
第12天 2016年7月18日 周一 组会+发布到Github
又是周一,又到了开组会的时间。这次组会还是先进行个人情况的汇报,然后大家一起观看计算几何的课程内容,这次的课程讲的是寻找凸包算法的优化,让复杂度降低了很多。
组会开完之后,戎烈锋学长又单独和我们一起交流了一下项目的工作进展,并给我们分配了新的任务。给符美潇分配的任务是在知识热点部分,增加曲线趋势评价,给我分配的任务是给搜索引擎的部分添加一个新的功能,对输入的搜索词,如果在维基百科中有相关的词条,则显示搜索词的简介,并且给出一个链接到维基百科词条的链接。
同时,学长说从这个星期开始,我们要统一Eclipse版本,并且把项目导入到GIthub上,方便进行代码的版本控制。正好我的Github可以创建私密的仓库,可以防止被外人看到,所以就由我来搭建仓库。
通过在网上搜索如何在Eclipse中使用git,我找到了了一篇博客文章,根据所写的步骤一步步完成了项目代码的上传,并尝试提交了一次修改。我根据这篇文章的内容,结合项目的情况,写了一篇比较详细教程发到了群里,供大家参考。有了git这么高效的工具,终于可以不用费力合并代码了。
第13天 2016年7月19日 周二 维基百科解释
项目上传到Github上后,我便开始制作用维基百科解释搜索词的功能。首先一个初步的打算是先找找有没有维基百科的API可以直接进行使用,如果没有,就只能通过抓取网页的方式进行。
使用Google搜索了一下,顺利找到了维基百科的API,这样事情就方便了很多。打开维基百科的API的首页,发现里面的内容有很多。通过一番查找和学习,终于找到了一个可以实现的方法:首先得到用户输入的搜索词;再调用API,查询词语在哪些词条出现过,API会返回一系列id;程序取出第一个id,也即是最接近该词语的一个词条,再次调用API,获得词条的简介内容和链接。
维基百科的API可以选择返回json格式或者xml格式,在网上找到一个处理json的包,应该比较方便,就学习了一下,直接拿来使用。之前也从来没有写过通过Java发送GET请求,也在网上找到了类似的代码,经过一番学习和修改,可以成功调用API。程序拿到简介内容,就可以显示在网页中了。我修改freemarker文件,加入了一个div标签,里面的内容是由传进来的wikicontent参数指定。在对应的Java函数中,将简介内容和链接通过setAttr()方法设置,就完成了。
这个功能实现起来比较简单,得益于有维基百科的API,以及现成的json处理库。实现的效果还可以,有一些缺点是由于维基百科采用https,两次发送请求会让网页打开速度有所降低,希望在以后的工作中能够解决这个问题。
第14天 2016年7月20日 周三 导出到Word
昨天项目进展比较顺利,所以今天戎烈锋学长给我分配了新的任务:给知识热点界面也加上维基百科解释,同时由于页面中增加了对热点趋势的评价,所以导出到word功能需要进行一定的修改。
给知识热点界面也加上维基百科解释,这个非常简单,直接复用昨天写的代码就好,当然还需要把知识热点界面加上显示维基百科简介的位置。
我之前有阅读过导出功能相关的代码,知道导出到word功能也是利用了freemarker的替换功能,将关键信息填写到对应位置,但是没有深入研究导出模板的内容。打开模板,我看到了一堆乱码一样的东西。在确定自己的打开方式正确以后,我开始仔细看里面的内容。最后发现,最后一行才是真正可读的内容,格式好像是xml。之前我也曾在闲暇时间阅读过关于office文件的格式的文档,现在发现这个格式和我当时阅读的内容很是接近。我把最后一行单独复制出来,手动将其化成有缩进的xml格式。整个文档的布局也就很清晰了。然后根据我的需要,插入了两个xml块,一个用来显示维基百科的内容和链接,另一个用来显示热点趋势评价,还是在Java中通过setAttr()方法传递内容。最后,我去掉换行符和制表符,整理成一行,替换原来的部分,成功完成今天的任务。
今天的任务需要一定的思考。也得益于我之前的阅读,让我能顺利完成这个功能。
第15天 2016年7月21日 周四 相关词汇优化
最近我们在测试搜索部分的各个功能,看有什么明显的问题。之前发现在搜索时,程序推荐的相关词汇有的时候会很奇怪,比如搜索deep learning,会出现一些没有意义的词组。今天戎烈锋学长给我的任务是优化相关词汇的结果。
之前阅读代码时,我主要看的是关于界面的代码,关于搜索的代码看得并不多。正好借这个机会,看看搜索的内部是怎么工作的,并且解决这个问题。我通过反推的方式,从存储结果的变量,找到修改这个变量的语句,进而找到了调用搜索的方法。所有关于搜索的内容都在SearchService类中。其实关于搜索的代码并不多,都是直接调用elasticsearch,并处理返回的结果。而相关词汇这部分,实际上做的非常简单:在数据库中找到返回结果的文章的关键词,进行词频统计,返回词频最高的5个。所以说出现的没有意义的词组也是关键词?我将所有关键词都打印了出来,发现果然有没有意义的关键词词组。我把这一情况告诉学长后,学长说数据库中有些数据确实有些问题,没有做数据清洗,让我试试能不能先通过一些处理先过滤掉这些词语。
我看了看关键词表,发现了一个特点,出现没有意义的关键词词组的论文,一般都有很多个关键词;而我们知道,一般论文的关键词不会超过5个。于是我在统计词频的地方加了一个判断,如果关键词超过5个,则该论文的关键词全部过滤。做完之后发现结果还不错。虽然改动不多,但是今天确实思考了很多。
第16天 2016年7月22日 周五 高级检索-多词检索
之前搜索部分有个功能,如果用户输入的是中文,在搜索时,会自动调用bing翻译API翻译成英文,再进行搜索。学长说在这种情况下,需要改成返回多个词,供用户选择采用哪个翻译结果,或者跳转到高级搜索界面进行多词检索。
既然要得到多个翻译结果,我先去bing API官网找了找有没有返回多个结果的API,结果网站上明确写着,中文不支持返回多词。只能看看别的翻译API了。终于,我在有道词典API的官网上,发现可以返回多个网络释义,也算是多个翻译结果吧。于是写了一个调用有道API的方法,处理返回的json串后,成功拿到了翻译结果。修改freemarker,让网页显示多个结果,并添加了一个按钮,跳转到高级检索界面。
然而高级检索界面还不支持传入参数,于是我又要对高级检索界面进行修改,通过getPara()方法接收参数,并显示到界面上。
终于做完了之后,我尝试将最近的代码提交到Github上去。结果发现出现了错误。根据错误信息,我先删除了jfinal.log的日志文件,再次提交。然后提示代码有冲突,我在网上搜索了一下,解决方法是这个时候只能手动合并代码。好在我的代码和符美潇的代码重合的地方并不多,根据git的指示简单改改就好了。于是顺利提交上了代码。
第17天 2016年7月25日 周一 科委开会+分配任务
今天童咏昕老师、戎烈锋学长、符美潇、我、还有两个学长,一起去北京市科委参加需求讨论会。之前也有这样的会议,由于我和符美潇对这个项目的深入,所以让我们也去听听需求方的意见,这样才能更好的完善我们的项目。
因为马上我们就要准备前沿技术部分的制作了,所以这次需求讨论会的主要目标是讨论清楚前沿技术这部分有哪些需求。戎烈锋学长先回顾了一下之前的项目进展,并进行了项目的演示。然后,我们就讨论了前沿技术的一些需求。我们的初步想法是,前沿技术分为发现和跟踪两个部分。发现部分是采用自然语言处理、数据挖掘、统计学等方法发现并查找出文献数据中蕴含的前沿技术;跟踪部分是用户输入一个需要跟踪的主题词,系统提示10个关键词,用户可以选择其中的若干个词或者手动输入词语,进行辅助检索。需求方觉得可行,并提出增加可视化展示的部分。
之后,我们又对前沿技术的定义进行了讨论。前沿技术应该具有以下特性:前瞻性,即未来有成为热点的潜力;先导性,即技术下位词很少或没有;探索性:研究热度呈上升趋势,但尚未到达拐点;高端性:概念由顶级会议、期刊或高等大学等知识聚集地发现和提出。明白了这些,对我们后续的工作有了很大的帮助。
第18天 2016年7月26日 周二 TF-IDF方法
今天,学长让我自学一下TF-IDF方法,说是为做前沿技术发现做准备。
通过相关资料的查阅,我知道了TF-IDF是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
在一份给定的文件里,词频TF指的是某一个给定的词语在该文件中出现的次数。逆向文件频率IDF是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
通过学习TF-IDF统计方法,可以找出文章里的易于区分的词汇,这些词语也很有可能是前沿科技词汇。总之,这个方法是否有效,需要到实际代码的编写中,才能知道效果好坏。
第19天 2016年7月27日 周三 LDA主题模型
今天,学长让我自学一下LDA主题模型,由于知识热点也采用这个方法,所以推荐我先去看看。
通过在互联网上搜索,我知道了LDA是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息。它采用了词袋的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
对于语料库中的每篇文档,LDA定义了如下生成过程:
1.对每一篇文档,从主题分布中抽取一个主题;
2.从上述被抽到的主题所对应的单词分布中抽取一个单词;
3.重复上述过程直至遍历文档中的每一个单词。
在推导和计算部分有很多公式,没有看得特别懂。但是,算法的过程基本上理解了,能够在需要的时候写出来。
第20天 2016年7月28日 周四 科技热点代码学习
今天,我和符美潇一起看了科技热点发现部分的代码。
根据学长写的指导文档和代码,我们明白了如何发现科技热点:
首先需要从数据库导出数据,以年为单位,在flkd项目seeds.rb中修改year这个变量。在flkd目录下运行rake db:seed 就能把对应年份的数据保存在设置的目录下。
然后是得到元数据,需要抽出生物医药和电子信息两个领域的数据,在data目录下g.rb脚本完成这一任务,最后分别存到bm(biomedicine)和ei(electronics)两个目录下。
接着将bm和ei目录拷贝到inspiration/ds中,接下来的工作都在inspiration下进行,这是ruby开发的一个命令行工具,包括数据预处理、跑LDA、主题命名,收集热点和新技术等。ruby process.rb 可以查看帮助信息。重要的参数是主题个数”-p”设置。process.rb是比较重要的脚本,它整合了所有的处理流程,如果某个阶段跑失败了,不必从头跑一篇,比较取巧的做法是把这个阶段之前的阶段注释掉,ruby用”=begin” “=end”注释块。
最终在bm文件夹下得到这些文本文件,其中201401.t1 表示一级热点,201401.t2表示二级热点,201401.aut 、201401.org对应的学者和机构 201401.nt表示新技术名词,201401.naut、 201401.norg为对应的学者和机构,将它们导入对应的数据表,就可以了。在数据表里人工筛选一下,一二级热点和新技术名词,明显不合适的就删除掉。
第21天 2016年7月29日 周五 前沿技术代码编写
今天我着手开始写前沿技术发现模块。之前和戎烈锋学长和童咏昕老师讨论了一下具体的实现,初步定的方法是先从数据库中取出最新一年的顶级期刊和论文,通过综合统计关键词和标题里的词语的热点走势情况,进行初步的筛选。然后对剩下的词语调用维基百科API,获得对应词条的编辑情况,再根据维基百科修订情况的数据,判断词语是否不是前沿技术。最后,再人工对结果进行筛选,得到最终的结果。
为了提高搜索速度,我决定直接调用elasticsearch从数据库中取出期刊和论文信息。关于如何从标题中分离出关键词,我的想法是根据停用词表对标题进行切割,得到的串应该就是关键词了。同时,关键词还存在单复数的问题,我从网上找了一个词元化的工具,顺利解决了这一问题。维基百科API我已经很熟悉了,再查查API首页,我也顺利找到了获取修订记录的方法。
整个过程看起来虽然容易,但实际做起来却不那么简单。工作量也很大,周五周六两天,我都在编写和调试这个代码。终于功夫不负有心人,我终于把它写完了。尝试跑了一遍结果,效果一般,仍然还需要进一步优化。
第22天 2016年8月1日 周一 分配任务+优化
今天,戎烈锋学长通知说没有组会。上午,我尝试对前沿技术发现模块进行优化。之前对标题的分词,采用的是用停用词进行分割。但是实际上,这样很有可能会得到形容词+名词的组合。为了解决这一问题,我一步步缩减单词长度,每次删去最左的一个词,直至这个词为空或者在数据库中被找到。这样提高了数据的准确性。
同时,我还观察了一下维基百科返回的数据,修订数据增加的内容用正数表示,删减的内容用负数表示。代码中统计年修订量的时候,直接相加了。正确的做法应该是取绝对值相加。这么做之后,也让结果准确了一些。
晚上,戎烈锋学长和我们开了一个小会。在交流了工作进度之后,戎烈锋学长分配给我这周的任务:一是制作前沿技术的发现的界面,二是制作前沿技术的追踪的界面,三是如果还有时间,优化一下之前的发现模块。
鉴于发现模块的结果还不是很准确,也许在后期需要更换算法,所以我决定先制作科技热点的发现和追踪的界面,先把界面画好,这样也不会显得没有进度。
第23天 2016年8月2日 周二 前沿技术发现界面
今天我来开始做前沿技术发现界面。其实前沿技术发现的界面比较简单,只需要把词语从数据库中取出并显示出来。这一部分可以复用科技热点发现的内容。
有所不同的是,这一部分需要能以分页的形式显示每一期的关键词。我觉得这个时候需要对数据库进行一些重新设计。记录前沿技术的数据库中没有记录是哪一年第几期,同时还需要一个总期数,以方便更好的进行处理。
所以,我先对数据库进行了一个备份,然后给数据库进行了一些修改。在原有的基础上,把hot_year换成了记录年份和期数的nt_year和nt_year_vol,还增加了一个总期数nt_vol。然后把原来的词语全部定义为2016年第1期和第2期。在获取某一页的数据时,会先从数据库获取总期数,计算该页对应的是第几期,然后从数据库获取这一期对应的信息,并显示到页面上。
另外,还要做一个上一期,下一期的链接。需要在显示的时候,知道当前要显示的是第几期,这样可以判断是否有上一期或下一期,也可以轻松更换链接的内容。今天的内容比较简单,所以很快就制作完成了。
第24天 2016年8月3日 周三 前沿技术跟踪界面1
今天我开始做前沿技术的跟踪部分的界面。需要做一个搜索框,在点击检索之后,找到相关的词汇,用户可以选择,来进行多个词的辅助搜索;用户也可以自己添加辅助搜索的词汇。
真正让我思考了一会的是如何制作自定义添加词语的模块。初步的想法是另外单独再做一个列表来显示。但是这样会使界面看起来很臃肿。所以后来我在想把自定义的词语和搜索找到的相关词汇放在同一个table里,这样比较简洁直观。那么如何动态添加表格呢?这里不能用freemarker的语法,因为它只在渲染界面的时候起作用。而添加的动作发生在网页加载完成的时候,所以我只能通过JavaScript或者jQuery来实现。这个时候需要在函数中动态改变HTML。经过查找,我发现jQuery中一个叫append()的函数可以在元素的末尾添加HTML内容,这正是我所需要的。我只需要判断新增的格子的位置,然后添加到正确的<tr></tr>或<td></td>中,这样就实现了功能。
还有一个改进是需要在一个图表中显示多个结果的曲线,我去EChart官网查询了相关的参数,直接修改参数就实现了这个功能。今天的工作量也不大,但是还是要认真仔细的做,这样用户界面才不会有太多问题。
第25天 2016年8月4日 周四 前沿技术跟踪界面2
今天我继续做前沿技术的跟踪部分的界面,争取在今天把大部分功能都实现了。今天要做的是显示关键词的相关领域、相关作者、相关机构的信息。之前知识热点部分是从数据库中进行检索,得到相关的信息。而对于前沿科技,数据库中相关的论文数量较少,得到的相关领域、相关作者、相关机构的信息不是很准确,所以我想从bing学术搜索中获得相关数据。
在网上搜寻了半天,发现bing学术搜索没有提供相关的API,所以只能自己通过抓取的方式获得数据。我先通过HTTP请求,获得整个网页的信息,存储到一个字符串中。接下来,通过网页的特征点,定位到截取数据的位置,在这里,我通过一个<span>标签就可以确定位置。然后我发现,数据全部在一个列表里,于是写了一个方法用于处理和获取<li>标签里的内容,由此,可以拿到数据。虽然看起来简单,但是涉及到字符串处理,写起来也是很费劲的。通过细心的调试和测试,终于能从网页爬到正确的数据。
接下来把数据显示到我们的网页上,我也做过很多遍这种类似的工作了。这次自然比以前更加熟练:在freemarker中用<#list>显示相关内容,在Java代码中用setAttr()方法设置数据。
今天的感受是,用Java做一个爬虫确实是很累,要观察HTML代码,还要在编码的时候非常细心。但也正是严谨细致的编码才能让项目做得更加完美。